PyTorch & Tensorflow: Semantic Segmentation of Underground Point Clouds with Transformer-based Neural Networks (In Progress)

Research Background
Nowadays, there is an existing wide range of application of deep learning in GIS field, these includes but not limited to navigation, autonomous driving, spatial analysis, and urban digital twin development, etc. (Qi et al., 2019). Most of existing methods have been adopted to either 2D or 3D outdoor data scenes for performance testing and comparison, but very few studies were conducted in a 3D indoor environment. Driven by the development of autonomous driving and urban advancement, there is an increasing need in the standardization of indoor 3D GI data/point clouds management. The following three research gaps are the driving forces that support me to build up the structure & design of my current thesis research.
Research Objectives


Dataset

qualified world-known large-scale indoor point cloud datasets from VGI will be used:
1) ModelNet40: CAD models in 40 object classes;
2) S3DIS: 271 rooms in six areas captured by 3D Matterport scanners;
3) ShapeNet: shapes represented by 3D CAD in 16 categories with 50 parts annotated;
4) ScanNet V2: 1513 scanned and reconstructed indoor scenes from RGBD cameras.
Since I am still at my early stage of research, a specific dataset has not been decided yet. My testing and training in later stage will use either one of the datasets listed above, or I might collect a small-scale indoor point cloud datasets if time is permissible.
Methodologies
The model that I am most likely to use for low-level tasking would be a modified PoinTr/ SnowflakeNet (Lu et al., 2022) whereas the model that I am most likely to use would be a modified stratified transformer (Lai et al., 2022) as stratified transformers outperform both Point transformer and PCT from existing studies in terms of preserving accuracy level and modelling long-range dependency, which is suitable for a dense point cloud dataset scene like S3DIS or ModelNet40.
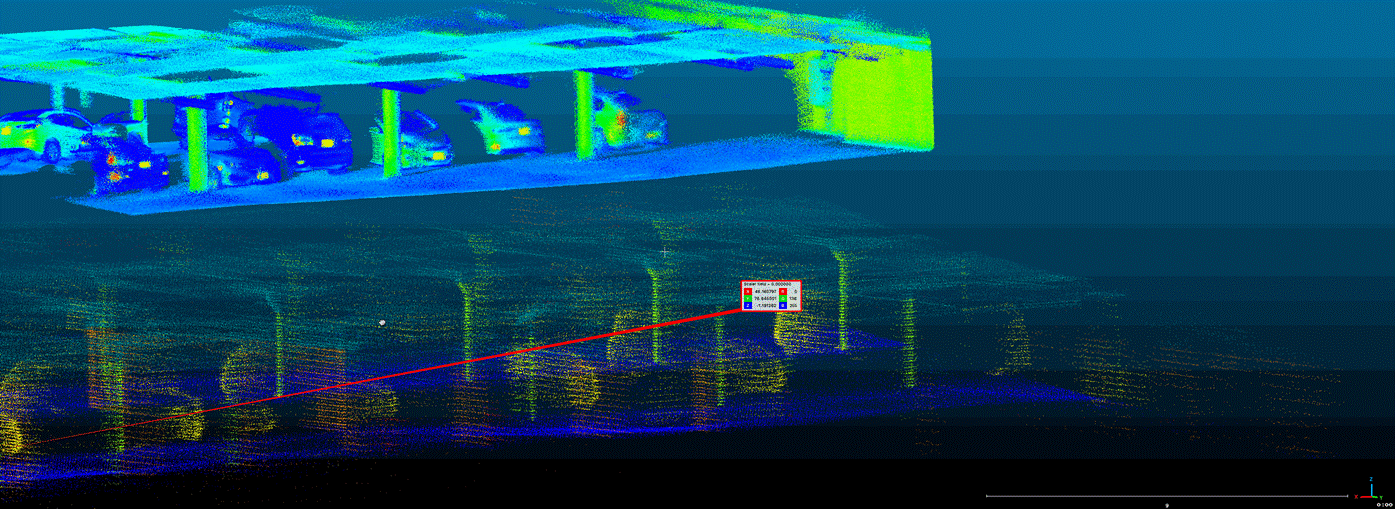
The reason why I choose a transformer-based model is simply because it fits with the inherent nature of point clouds, which would potentially have few effects to the overall performances since they are both permutation & order invariant for processing sequences of points (Guo et al., 2021). This means transformer models suits point cloud processing perfectly and there would be a great potential in future application with combining these two fields.
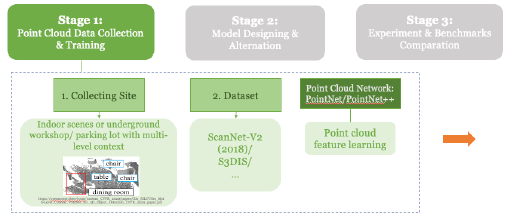
Stage 01: Transformer Testing & Environment Setup for PC Processing
Stage 02: Model Design & Alteration (if needed)
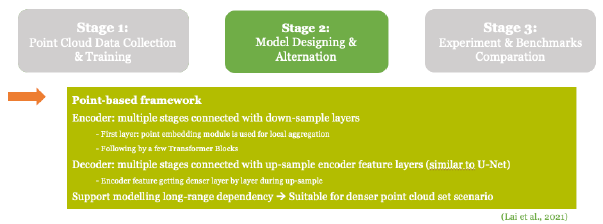
Additional: Explore the potential of combining point-based convolution + transformer*
Since spatial transformer (Wang et al., 2021) can enhance model learning ability as well as optimize local neighbor adapted at each layer, I would try to explore the potential in combining this algorithm with proposed method in a small term project to see whether the output outperform original (current) transformer-based method (e.g. substitute traditional [self-attention + FFN] transformer blocks with similar blocks like “spatial transformer blocks”).
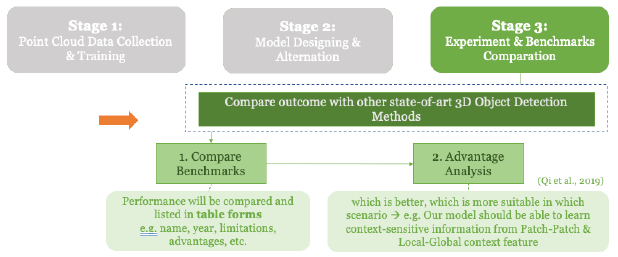
Stage 03: Experiment & Benchmark Performance Comparation
References
C. Zhang, H. Wan, X. Shen, and Z. Wu, “PVT: Point-Voxel Transformer for Point Cloud Learning.” arXiv, May 25, 2022. Accessed: Sep. 02, 2022. [Online]. Available: http://arxiv.org/abs/2108.06076
D. Lu, Q. Xie, M. Wei, L. Xu, and J. Li (2022), “Transformers in 3D Point Clouds: A Survey,” IEEE IEEE Trans. Pattern Anal. Mach. Intell., p. 24., retrieve from https://arxiv.org/pdf/2205.07417
Guo, Y., Wang, H., Hu, Q., Liu, H., Liu, L., & Bennamoun, M. (2020). Deep Learning for 3D Point Clouds: A Survey (arXiv:1912.12033). arXiv. http://arxiv.org/abs/1912.12033
H. Zhao, L. Jiang, J. Jia, P. H. S. Torr, and V. Koltun, “Point Transformer,” IEEE/CVF International Conference on Computer Vision (ICCV)
Lehtola, V., Kaartinen, H., Nüchter, A., Kaijaluoto, R., Kukko, A., Litkey, P., Honkavaara, E., Rosnell, T., Vaaja, M., Virtanen, J.-P., Kurkela, M., El Issaoui, A., Zhu, L., Jaakkola, A., & Hyyppä, J. (2017). Comparison of the Selected State-Of-The-Art 3D Indoor Scanning and Point Cloud Generation Methods. Remote Sens., 9(8), 796. https://doi.org/10.3390/rs9080796
Li, C., Jiang, Y., & Cheslyar, M. (2018). Embedding Image Through Generated Intermediate Medium Using Deep Convolutional Generative Adversarial Network. 13.
Qian, R., Lai, X., & Li, X. (2021). 3D Object Detection for Autonomous Driving: A Survey (arXiv:2106.10823). arXiv. http://arxiv.org/abs/2106.10823
Radford, A., Metz, L., & Chintala, S. (2016). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (arXiv:1511.06434). arXiv. http://arxiv.org/abs/1511.06434
R. Strudel, R. Garcia, I. Laptev, and C. Schmid, “Segmenter: Transformer for Semantic Segmentation,” in 2021 IEEE/ICCV, Montreal, QC, Canada, Oct. 2021, pp. 7242–7252. doi: 10.1109/ICCV48922.2021.00717.
X. Lai et al., “Stratified Transformer for 3D Point Cloud Segmentation,” IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), p. 10.
Zeng, J., Wang, D., & Chen, P. (2022). A Survey on Transformers for Point Cloud Processing: An Updated Overview. IEEE Access, 10, 86510-86527.